文章转自:
1.1Hadoop是什么
Hadoop原来是Apache Lucene下的一个子项目,它最初是从Nutch项目中分离出来的专门负责分布式存储以及分布式运算的项目。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。下面列举hadoop主要的一些特点:
![]() 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
![]() 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
![]() 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
![]() 可靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
可靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
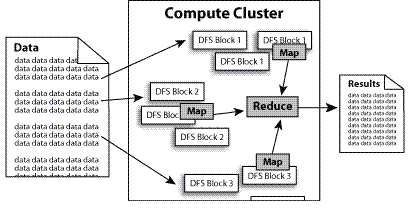
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
Hadoop还实现了MapReduce分布式计算模型。MapReduce将应用程序的工作分解成很多小的工作小块(small blocks of work)。HDFS为了做到可靠性(reliability)创建了多份数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(compute nodes),MapReduce就可以在它们所在的节点上处理这些数据了。
如下图所示:
Hadoop API被分成(divide into)如下几种主要的包(package):
![]() org.apache.hadoop.conf 定义了系统参数的配置文件处理API。
org.apache.hadoop.conf 定义了系统参数的配置文件处理API。
![]() org.apache.hadoop.fs 定义了抽象的文件系统API。
org.apache.hadoop.fs 定义了抽象的文件系统API。
![]() org.apache.hadoop.dfs Hadoop分布式文件系统(HDFS)模块的实现。
org.apache.hadoop.dfs Hadoop分布式文件系统(HDFS)模块的实现。
![]() org.apache.hadoop.io 定义了通用的I/O API,用于针对网络,数据库,文件等数据对象做读写操作。
org.apache.hadoop.io 定义了通用的I/O API,用于针对网络,数据库,文件等数据对象做读写操作。
![]() org.apache.hadoop.ipc 用于网络服务端和客户端的工具,封装了网络异步I/O的基础模块。
org.apache.hadoop.ipc 用于网络服务端和客户端的工具,封装了网络异步I/O的基础模块。
![]() org.apache.hadoop.mapred Hadoop分布式计算系统(MapReduce)模块的实现,包括任务的分发调度等。
org.apache.hadoop.mapred Hadoop分布式计算系统(MapReduce)模块的实现,包括任务的分发调度等。
![]() org.apache.hadoop.metrics 定义了用于性能统计信息的API,主要用于mapred和dfs模块。
org.apache.hadoop.metrics 定义了用于性能统计信息的API,主要用于mapred和dfs模块。
![]() org.apache.hadoop.record 定义了针对记录的I/O API类以及一个记录描述语言翻译器,用于简化将记录序列化成语言中性的格式(language-neutral manner)。
org.apache.hadoop.record 定义了针对记录的I/O API类以及一个记录描述语言翻译器,用于简化将记录序列化成语言中性的格式(language-neutral manner)。
![]() org.apache.hadoop.tools 定义了一些通用的工具。
org.apache.hadoop.tools 定义了一些通用的工具。
![]() org.apache.hadoop.util 定义了一些公用的API。
org.apache.hadoop.util 定义了一些公用的API。
1.2 Hadoop的框架结构
Map/Reduce是一个用于大规模数据处理的分布式计算模型,它最初是由Google工程师设计并实现的,Google已经将它完整的MapReduce论文公开发布了。其中对它的定义是,Map/Reduce是一个编程模型(programming model),是一个用于处理和生成大规模数据集(processing and generating large data sets)的相关的实现。用户定义一个map函数来处理一个key/value对以生成一批中间的key/value对,再定义一个reduce函数将所有这些中间的有着相同key的values合并起来。很多现实世界中的任务都可用这个模型来表达。
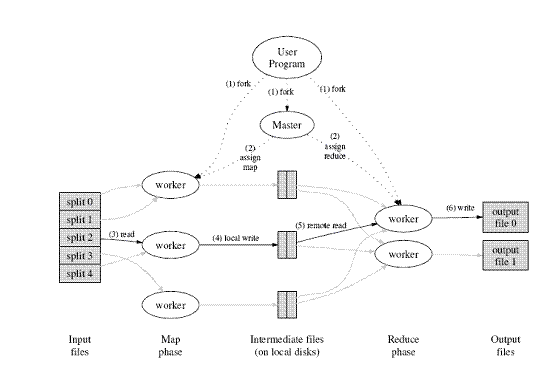 Map/Reduce模型计算示意图
Map/Reduce模型计算示意图
Hadoop的Map/Reduce框架也是基于这个原理实现的。